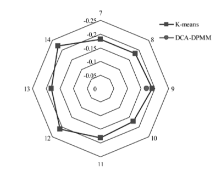
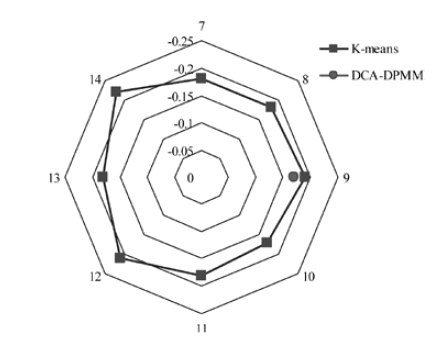
| [1] |
Jiawei H, Kamber M.Data Mining Concepts and Techniques (Third Edition)[M]. San Francisco: Morgan Kaufmann, 2011.
|
| [2] |
Hartigan J A, Wong M A.Algorithm AS 136: A k-means Clustering Algorithm[J]. Applied Statistics, 1979, 28(1): 100-108.
|
| [3] |
Bouman C A, Shapiro M, Cook G W, et al. Cluster: An Unsupervised Algorithm for Modeling Gaussian Mixtures [EB/OL].Online available 2015-8-16.
|
| [4] |
Sharif-Razavian N, Zollmann A. An Overview of Nonparametric Bayesian Models and Applications to Natural Language Processing [EB/OL]. Online available: 2015-8-16.
|
| [5] |
Teh Y W, Jordan M I, Beal M J, et al.Hierarchical Dirichlet Processes[J]. Journal of the American Statistical Association, 2006, 101(476): 1566-1581.
|
| [6] |
Vlachos A, Korhonen A, Ghahramani Z.Unsupervised and Constrained Dirichlet Process Mixture Models for Verb Clustering[C]//Proceedings of the Workshop on Geometrical Models of Natural Language Semantics. Association for Computational Linguistics, 2009: 74-82.
|
| [7] |
Fox E B, Choi D S, Willsky A S.Nonparametric Bayesian Methods for Large Scale Multi-target Tracking[C]//ACSSC'06. Fortieth Asilomar Conference on Signals, Systems and Computers. IEEE, 2006: 2009-2013.
|
| [8] |
Zhang Z H, Dai G, Jordan M I.Matrix-variate Dirichlet Process Mixture Models[C]// Proceedings of the 13th International Conference on Artificial Intelligence and Statistics. Sardinia, Italy: The MIT Press, 2010:980-987
|
| [9] |
Ferguson T S.A Bayesian Analysis of Some Nonparametric Problems[J]. The Annals of Statistics, 1973, 1(2): 209-230.
|
| [10] |
Teh Y W.Dirichlet Process[M]. Springer US, 2010.
|
| [11] |
Pitman J.Poisson-Dirichlet and GEM Invariant Distributions for Split-and-merge Transformation of an Interval Partition[J]. Combinatorics, Probability and Computing, 2002, 11(5): 501-514.
|
| [12] |
Blackwell D, MacQueen J B. Ferguson Distributions via Polya Urn Schemes[J]. The Annals of Statistics, 1973, 1(2): 353-355.
|
| [13] |
Pitman J.Combinatorial Stochastic Processes[R]. California: UC Berkeley, Lecture notes for St. Flour course, 2002.
|
| [14] |
Neal R M.Bayesian Mixture Modeling Maximum Entropy and Bayesian Methods[M].Springer Netherlands, 1992.
|
| [15] |
孙兴东,李爱平,李树栋. 一种基于聚类的微博关键词提取方法的研究与实现[J]. 信息网络安全,2014,(12):27-31.
|
| [16] |
John M.Inference for Dirichlet-Multinomials and Dirichlete Processes [R].Sydney: Macquarie University, 2011.
|
| [17] |
曹彬,顾怡立,谢珍真,等. 一种基于大数据技术的舆情监控系统[J]. 信息网络安全,2014,(12):32-36.
|
| [18] |
Neal R M.Markov Chain Sampling Methods for Dirichlet Process Mixture Models[J]. Journal of Computational and Graphical Statistics, 2000, 9(2): 249-265.
|
| [19] |
陈晓,赵晶玲. 大数据处理中混合型聚类算法的研究与实现[J]. 信息网络安全,2015,(4):45-49.
|
| [20] |
Moh'd B A Z, Rawi M. An Efficient Approach for Computing Silhouette Coefficients[J]. Journal of Computer Science, 2008, 4(3): 252-255.
|
| [21] |
Blei D M, Ng A Y, Jordan M I.Latent Dirichlet Allocation[J]. Journal of Machine Learning Research, 2003, 4(3): 993-1022.
|