Netinfo Security ›› 2025, Vol. 25 ›› Issue (10): 1627-1638.doi: 10.3969/j.issn.1671-1122.2025.10.013
Previous Articles Next Articles
Research on Cross Form Similarity Detection for C/C++ Code
WANG Yanxin, JIA Peng( ), FAN Ximing, PENG Xi
), FAN Ximing, PENG Xi
- School of Cyber Science and Engineering, Sichuan University, Chengdu 610065, China
-
Received:2025-05-10Online:2025-10-10Published:2025-11-07 -
Contact:JIA Peng E-mail:pengjia@scu.edu.cn
CLC Number:
Cite this article
WANG Yanxin, JIA Peng, FAN Ximing, PENG Xi. Research on Cross Form Similarity Detection for C/C++ Code[J]. Netinfo Security, 2025, 25(10): 1627-1638.
share this article
Add to citation manager EndNote|Ris|BibTeX
URL: http://netinfo-security.org/EN/10.3969/j.issn.1671-1122.2025.10.013

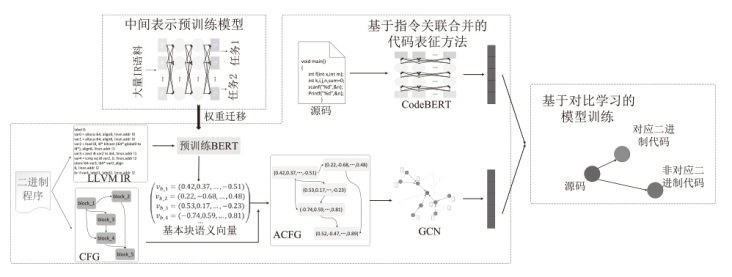




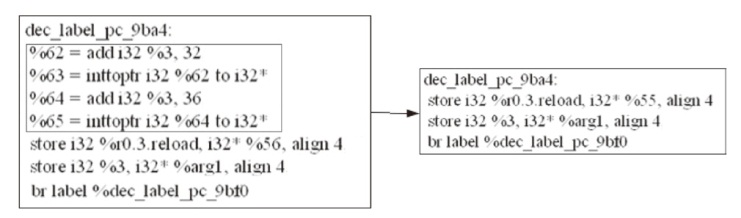
| 场景 | 同优化级别 | 同架构 | 同编译器 |
|---|---|---|---|
| XO | × | √ | √ |
| XA | √ | × | √ |
| XC | √ | √ | × |
| XO+XA | × | × | √ |
| XO+XC | × | √ | × |
| XA+XC | √ | × | × |
| XO+XA+XC | × | × | × |
| 场景 | 本文方法 | B2SFinder | BinPro | XLIR | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| XO | 97.1% | 90.2% | 93.5% | 76.7% | 8.7% | 15.6% | 98.6% | 34.2% | 50.8% | 89.6% | 88.9% | 89.2% |
| XA | 96.8% | 90.9% | 93.7% | 83.3% | 6.5% | 12.1% | 97.8% | 22.4% | 36.5% | 89.1% | 88.2% | 88.6% |
| XC | 96.4% | 91.1% | 93.7% | 74.2% | 8.7% | 15.6% | 99.1% | 38.2% | 55.2% | 88.6% | 89.2% | 88.9% |
| XO+XA | 96.9% | 89.7% | 93.1% | 80.6% | 6.3% | 11.7% | 97.6% | 23.5% | 37.9% | 88.7% | 88.5% | 88.6% |
| XO+XC | 97.0% | 90.0% | 93.4% | 67.2% | 8.5% | 15.1% | 98.9% | 37.0% | 53.8% | 89.2% | 87.9% | 88.5% |
| XA+XC | 97.1% | 90.8% | 93.9% | 78.9% | 6.3% | 11.7% | 97.9% | 31.6% | 47.8% | 88.3% | 87.6% | 87.9% |
| XO+XA+ XC | 97.1% | 89.8% | 93.3% | 72.0% | 6.2% | 11.4% | 98.5% | 35.3% | 51.9% | 87.7% | 87.6% | 87.6% |
| 场景 | 本文方法 | B2SFinder | BinPro | XLIR | ||||
|---|---|---|---|---|---|---|---|---|
| s2b | b2s | s2b | b2s | s2b | b2s | s2b | b2s | |
| XO | 80.2% | 82.5% | 23.8% | 25.7% | 27.4% | 18.8% | 75.6% | 78.9% |
| XA | 81.1% | 83.5% | 33.2% | 21.7% | 24.4% | 19.8% | 76.1% | 78.9% |
| XC | 80.1% | 83.3% | 23.1% | 25.7% | 23.6% | 19.0% | 75.9% | 78.7% |
| XO+XA | 76.9% | 81.8% | 28.9% | 21.7% | 26.1% | 18.7% | 74.5% | 78.5% |
| XO+XC | 76.5% | 82.2% | 20.6% | 25.7% | 26.2% | 18.2% | 74.6% | 78.3% |
| XA+XC | 77.1% | 83.2% | 30.0% | 22.6% | 23.6% | 18.8% | 74.1% | 78.6% |
| XO+XA+XC | 74.4% | 82.0% | 28.5% | 22.6% | 25.0% | 18.1% | 73.3% | 78.2% |
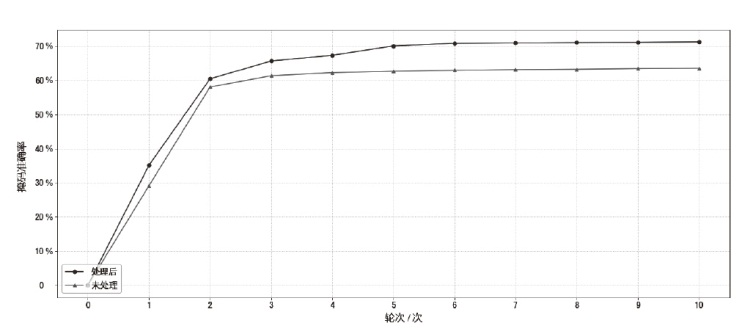
| 场景 | 无预训练 | 有预训练 | ||||
|---|---|---|---|---|---|---|
| 精确率 | 召回率 | F1值 | 精确率 | 召回率 | F1值 | |
| XO | 92.8% | 88.0% | 91.8% | 97.1% | 90.2% | 93.5% |
| XA | 94.1% | 89.5% | 91.8% | 96.8% | 90.9% | 93.7% |
| XC | 92.8% | 89.5% | 91.1% | 96.4% | 91.1% | 93.7% |
| XO+XA | 92.4% | 87.9% | 90.1% | 96.9% | 89.7% | 93.1% |
| XO+XC | 92.6% | 88.4% | 90.4% | 97.0% | 90.0% | 93.4% |
| XA+XC | 92.9% | 89.4% | 91.1% | 97.1% | 90.8% | 93.9% |
| XO+XA+XC | 92.9% | 88.3% | 90.6% | 97.1% | 89.8% | 93.3% |

| [1] | MIYANI D, HUANG Zhen, LIE D. Binpro: A Tool for Binary Source Code Provenance[EB/OL]. (2017-11-02)[2025-03-05]. https://arxiv.org/abs/1711.00830. |
| [2] | SHAHKAR A. On Matching Binary to Source Code[D]. Montreal: Concordia University, 2016. |
| [3] | ASLANYAN H, MOVSISYAN H, ARUTUNIAN M, et al. Bin2Source: Matching Binary to Source Code[C]// IEEE. 2021 Ivannikov ISPRAS Open Conference (ISPRAS). New York: IEEE, 2021: 3-7. |
| [4] | DUAN Ruian, BIJLANI A, XU Meng, et al. Identifying Open-Source License Violation and 1-Day Security Risk at Large Scale[C]// ACM. The 2017 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2017: 2169-2185. |
| [5] | WANG Wenhan, LI Ge, MA Bo, et al. Detecting Code Clones with Graph Neural Network and Flow-Augmented Abstract Syntax Tree[C]// IEEE. 2020 IEEE 27th International Conference on Software Analysis, Evolution and Reengineering (SANER). New York: IEEE, 2020: 261-271. |
| [6] | ZHAO Gang, HUANG J. Deepsim: Deep Learning Code Functional Similarity[C]// ACM. The 2018 26th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York: ACM, 2018: 141-151. |
| [7] | CHANDRAMOHAN M, XUE Yinxing, XU Zhengzi, et al. Bingo: Cross-Architecture Cross-OS Binary Search[C]// ACM. The 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering. New York: ACM, 2016: 678-689. |
| [8] | ZUO Fei, LI Xiaopeng, YOUNG P, et al. Neural Machine Translation Inspired Binary Code Similarity Comparison beyond Function Pairs[EB/OL]. (2018-08-08)[2025-03-05]. https://arxiv.org/abs/1808.04706. |
| [9] | YU Zeping, ZHENG Wenxin, WANG Jiaqi, et al. Codecmr: Cross-Modal Retrieval for Function-Level Binary Source Code Matching[J]. Advances in Neural Information Processing Systems, 2020, 33: 3872-3883. |
| [10] | GUI Yi, WAN Yao, ZHANG Hongyu, et al. Cross-Language Binary-Source Code Matching with Intermediate Representations[C]// IEEE. 2022 IEEE International Conference on Software Analysis, Evolution and Reengineering (SANER). New York: IEEE, 2022: 601-612. |
| [11] | JIANG Ling, AN Junwen, HUANG Huihui, et al. BinaryAI: Binary Software Composition Analysis via Intelligent Binary Source Code Matching[C]// ACM. The IEEE/ACM 46th International Conference on Software Engineering. New York: ACM, 2024: 1-13. |
| [12] | PHAN H N, PHAN H N, NGUYEN T N, et al. Repohyper: Better Context Retrieval is All You Need for Repository-Level Code Completion[EB/OL]. (2024-08-14)[2025-03-05]. https://arxiv.org/abs/2403.06095. |
| [13] | EGHBALI A, PRADEL M. De-Hallucinator: Iterative Grounding for LLM-Based Code Completion[EB/OL]. (2024-06-19)[2025-03-05]. https://jespereggers.com/wp-content/uploads/2024/10/De-Hallucinator-Iterative-Grounding-for-LLM-Based-Code-1.pdf. |
| [14] | ZHANG Fengji, CHEN Bei, ZHANG Yue, et al. Repocoder: Repository-Level Code Completion through Iterative Retrieval and Generation[EB/OL]. (2023-10-20)[2025-03-05]. https://arxiv.org/abs/2303.12570. |
| [15] | GU Xiaodong, ZHANG Hongyu, KIM S. Deep Code Search[C]// ACM. The 40th International Conference on Software Engineering. New York: ACM, 2018: 933-944. |
| [16] | HUSAIN H, WU H H, GAZIT T, et al. Codesearchnet Challenge: Evaluating the State of Semantic Code Search[EB/OL]. (2020-06-08)[2025-03-05]. https://arxiv.org/abs/1909.09436. |
| [17] | ZHANG Xiaochuan, SUN Wenjie, PANG Jianmin, et al. Similarity Metric Method for Binary Basic Blocks of Cross-Instruction Set Architecture[EB/OL]. (2020-02-23)[2025-03-05]. https://www.ndss-symposium.org/wp-content/uploads/2020/04/bar2020-23002.pdf. |
| [18] | TANG Ze, SHEN Xiaoyu, LI Chuan, et al. Ast-Trans: Code Summarization with Efficient Tree-Structured Attention[C]// ACM. The 44th International Conference on Software Engineering. New York: ACM, 2022: 150-162. |
| [19] | JOHNSON R, ZHANG Tong. Deep Pyramid Convolutional Neural Networks for Text Categorization[EB/OL]. [2025-03-05]. https://aclanthology.org/P17-1052/. |
| [20] | FENG Zhangyin, GUO Daya, TANG Duyu, et al. Codebert: A Pre-Trained Model for Programming and Natural Languages[EB/OL]. (2020-09-18)[2025-03-05]. https://arxiv.org/abs/2002.08155. |
| [21] | DING Yangruibo, CHAKRABORTY S, BURATTI L, et al. CONCORD: Clone-Aware Contrastive Learning for Source Code[C]// ACM. The 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis. New York: ACM, 2023: 26-38. |
| [22] | NIU Chang’an, LI Chuanyi, NG V, et al. Spt-Code: Sequence-to-Sequence Pre-Training for Learning Source Code Representations[C]// ACM. The 44th International Conference on Software Engineering. New York: ACM, 2022: 2006-2018. |
| [23] | ZHANG Jian, WANG Xu, ZHANG Hongyu, et al. A Novel Neural Source Code Representation Based on Abstract Syntax Tree[C]// IEEE. 2019 IEEE/ACM 41st International Conference on Software Engineering (ICSE). New York: ACM, 2019: 783-794. |
| [24] | GUO Daya, REN Shuo, LU Shuai, et al. GraphCodeBert: Pre-Training Code Representations with Data Flow[EB/OL]. (2021-09-13)[2025-03-05]. https://arxiv.org/abs/2009.08366. |
| [25] | LIU Jiahao, ZENG Jun, WANG Xiang, et al. Learning Graph-Based Code Representations for Source-Level Functional Similarity Detection[C]// IEEE. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE). New York: IEEE, 2023: 345-357. |
| [26] | FENG Qian, ZHOU Rundong, XU Chengcheng, et al. Scalable Graph-Based Bug Search for Firmware Images[C]// ACM. The 2016 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2016: 480-491. |
| [27] | XU Xiaojun, LIU Chang, FENG Qian, et al. Neural Network-Based Graph Embedding for Cross-Platform Binary Code Similarity Detection[C]// ACM. The 2017 ACM SIGSAC Conference on Computer and Communications Security. New York: ACM, 2017: 363-376. |
| [28] | YU Zeping, CAO Rui, TANG Qiyi, et al. Order Matters: Semantic-Aware Neural Networks for Binary Code Similarity Detection[C]// AAAI. Proceedings of the AAAI Conference on Artificial Intelligence. Menlo Park: AAAI, 2020: 1145-1152. |
| [29] | KIM G, HONG S, FRANZ M, et al. Improving Cross-Platform Binary Analysis Using Representation Learning via Graph Alignment[C]// ACM. Proceedings of the 31st ACM SIGSOFT International Symposium on Software Testing and Analysis. New York: ACM, 2022: 151-163. |
| [30] | SHALEV N, PARTUSH N. Binary Similarity Detection Using Machine Learning[C]// ACM. Proceedings of the 13th Workshop on Programming Languages and Analysis for Security. New York: ACM, 2018: 42-47. |
| [31] | Zynamics. BinDiff[EB/OL]. [2025-03-05]. https://www.zynamics.com/bindiff.html. |
| [32] | PEI Kexin, XUAN Zhou, YANG Junfeng, et al. Trex: Learning Execution Semantics from Micro-Traces for Binary Similarity[EB/OL]. (2021-03-26)[2025-03-05]. https://arxiv.org/abs/2012.08680. |
| [33] | LUO Zhenhao, WANG Pengfei, WANG Baosheng, et al. VulHawk: Cross-Architecture Vulnerability Detection with Entropy-Based Binary Code Search[EB/OL]. (2023-02-27)[2025-03-05]. https://www.ndss-symposium.org/wp-content/uploads/2023/02/ndss2023_f415_paper.pdf. |
| [34] | JI Yuede, CUI Lei, HUANG H H. Buggraph: Differentiating Source-Binary Code Similarity with Graph Triplet-Loss Network[C]// ACM. Proceedings of the 2021 ACM Asia Conference on Computer and Communications Security. New York: ACM, 2021: 702-715. |
| [35] | TEHRANIJAMSAZ A, CHEN Hanze, JANNESARI A. Graphbinmatch: Graph-Based Similarity Learning for Cross-Language Binary and Source Code Matching[C]// IEEE. 2024 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW). New York: IEEE, 2024: 506-515. |
| [36] | Hugging Face. Hugging Face[EB/OL]. [2025-03-05]. https://huggingface.co/. |
| [37] | ALLAMANIS M. Graph Neural Networks in Program Analysis[EB/OL]. (2022-01-03)[2025-03-05]. https://link.springer.com/chapter/10.1007/978-981-16-6054-2_22. |
| [38] | ALLAMANIS M, BROCKSCHMIDT M, KHADEMI M. Learning to Represent Programs with Graphs[EB/OL]. (2018-05-04)[2025-03-05]. https://arxiv.org/abs/1711.00740. |
| [39] | CUMMINS C, FISCHES Z V, BEN-NUN T, et al. Programl: Graph-Based Deep Learning for Program Optimization and Analysis[EB/OL]. (2020-03-23)[2025-03-05]. https://arxiv.org/abs/2003.10536. |
| [40] | KIPF T N, WELLING M. Semi-Supervised Classification with Graph Convolutional Networks[EB/OL]. (2017-02-22)[2025-03-05]. https://arxiv.org/abs/1609.02907. |
| [41] | MARCELLI A, GRAZIANO M, UGARTE-PEDRERO X, et al. How Machine Learning is Solving the Binary Function Similarity Problem[C]// USENIX. The 31st USENIX Security Symposium (USENIX Security’22). Berkeley: USENIX, 2022: 2099-2116. |
| [42] | POWERS D M W. Evaluation: from Precision, Recall and F-Measure to ROC, Informedness, Markedness and Correlation[EB/OL]. (2020-10-11)[2025-03-05]. https://arxiv.org/abs/2010.16061. |
| [43] | YUAN Zimu, FENG Muyue, LI Feng, et al. B2sfinder: Detecting Open-Source Software Reuse in Cots Software[C]// IEEE. 2019 34th IEEE/ACM International Conference on Automated Software Engineering (ASE). New York: IEEE, 2019: 1038-1049. |
| [1] | HU Bin, HEI Yiming, WU Tiejun, ZHENG Kaifa, LIU Wenzhong. A Review of Safety Detection and Evaluation Technologies for Large Models [J]. Netinfo Security, 2025, 25(10): 1477-1492. |
| [2] | ZHANG Dalong, DING Shuguang, HAN Zhilong, FU Shouli, TANG Zhiqing, SHI Lei. Review of Cyber Resilience Assessment Framework and Methods [J]. Netinfo Security, 2025, 25(10): 1493-1505. |
| [3] | LAN Jiachen, CHEN Xiarun, ZHOU Yangkai, WEN Weiping. A Survey of Routing Technologies and Protocols in Polymorphic Networks [J]. Netinfo Security, 2025, 25(10): 1506-1522. |
| [4] | YU Fajiang, WANG Chaozhou. Implementation Mechanism for TrustZone Paravirtualization and Containerization [J]. Netinfo Security, 2025, 25(10): 1523-1536. |
| [5] | TAO Ci, WANG Yi, ZHANG Lei, CHEN Ping. Fuzz Testing Method for Firmware in Cloud-Edge Collaborative Scenarios [J]. Netinfo Security, 2025, 25(10): 1537-1545. |
| [6] | XIE Sijiang, FENG Yan, YAN Yalong, NING Fei. Research on Universal Service Mode of Quantum Key Based on Dual Key Synchronization [J]. Netinfo Security, 2025, 25(10): 1546-1553. |
| [7] | LI Guyue, ZHANG Zihao, MAO Chenghai, LYU Rui. A Cumulant-Deep Learning Fusion Model for Underwater Modulation Recognition [J]. Netinfo Security, 2025, 25(10): 1554-1569. |
| [8] | HU Longhui, SONG Hong, WANG Weiping, YI Jia, ZHANG Zhixiong. Research on the Application of Large Language Model in False Positive Handling for Managed Security Services [J]. Netinfo Security, 2025, 25(10): 1570-1578. |
| [9] | WANG Youhe, SUN Yi. Multi-Feature Fusion for Malicious PDF Document Detection Based on CNN-BiLSTM-CBAM [J]. Netinfo Security, 2025, 25(10): 1579-1588. |
| [10] | ZHANG Lu, JIA Peng, LIU Jiayong. Binary Code Similarity Detection Method Based on Multivariate Semantic Graph [J]. Netinfo Security, 2025, 25(10): 1589-1603. |
| [11] | LIANG Fengmei, PAN Zhenghao, LIU Ajian. A Joint Detection Method for Physical and Digital Face Attacks Based on Common Forgery Clue Awareness [J]. Netinfo Security, 2025, 25(10): 1604-1614. |
| [12] | LI Tao, CHENG Baifeng. Research on Network Asset Identification Technology Based on Graph Neural Network [J]. Netinfo Security, 2025, 25(10): 1615-1626. |
| [13] | ZHAN Dongyang, HUANG Zilong, TAN Kai, YU Zhaofeng, HE Zheng, ZHANG Hongli. Cross-Function Behavior Analysis and Constraint Technology for Serverless Applications [J]. Netinfo Security, 2025, 25(9): 1329-1337. |
| [14] | CAO Jun, XIANG Ga, REN Yawei, TAN Zicheng, YANG Qunsheng. Small-Sample APT Attack Event Extraction Method Based on Large Model [J]. Netinfo Security, 2025, 25(9): 1338-1347. |
| [15] | HU Yucui, GAO Haotian, ZHANG Jie, YU Hang, YANG Bin, FAN Xuejian. Automated Exploitation of Vulnerabilities in Vehicle Network Security [J]. Netinfo Security, 2025, 25(9): 1348-1356. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||