信息网络安全 ›› 2025, Vol. 25 ›› Issue (8): 1254-1262.doi: 10.3969/j.issn.1671-1122.2025.08.007
基于多智能体对抗学习的攻击路径发现方法
张国敏, 张俊峰( ), 屠智鑫, 王梓澎
), 屠智鑫, 王梓澎
- 陆军工程大学指挥控制工程学院,南京 210001
-
收稿日期:2024-09-13出版日期:2025-08-10发布日期:2025-09-09 -
通讯作者:张俊峰 E-mail:zhjf0317@163.com -
作者简介:张国敏(1979—),男,山东,副教授,博士,主要研究方向为软件定义网络、网络安全、网络测量和分布式系统|张俊峰(1995—),男,山东,硕士研究生,主要研究方向为网络安全|屠智鑫(1997—),男,江苏,硕士研究生,主要研究方向为网络安全|王梓澎(2000—),男,辽宁,硕士研究生,主要研究方向为网络安全 -
基金资助:国家自然科学基金(62172432)
An Attack Path Discovery Method Based on Multi-Agent Adversarial Learning
ZHANG Guomin, ZHANG Junfeng(), TU Zhixin, WANG Zipeng
- Institute of Command and Control Engineering, Army Engineering University of PLA, Nanjing 210001, China
-
Received:2024-09-13Online:2025-08-10Published:2025-09-09
摘要:
攻击路径发现是智能化渗透测试的一项重要技术,由于安防机制触发、安防人员介入等原因,目标网络往往处于动态变化状态,然而现有研究方法基于静态虚拟网络环境进行训练,智能体因经验失效问题难以适应环境的改变。为此,文章设计了一种基于完全竞争的智能体对抗博弈框架AGF,模拟红方在动态防御网络中攻击路径发现的红蓝智能体对抗博弈过程,并在PPO算法的基础上提出带有防御响应感知(DRP)机制的改进型算法PPODRP对状态和动作进行规划处理,从而使智能体具备对动态环境的适应性。实验结果表明,相比传统PPO算法,PPODRP方法在动态防御网络中的收敛效率更高,能够以更小的代价完成攻击路径发现任务。
中图分类号:
引用本文
张国敏, 张俊峰, 屠智鑫, 王梓澎. 基于多智能体对抗学习的攻击路径发现方法[J]. 信息网络安全, 2025, 25(8): 1254-1262.
ZHANG Guomin, ZHANG Junfeng, TU Zhixin, WANG Zipeng. An Attack Path Discovery Method Based on Multi-Agent Adversarial Learning[J]. Netinfo Security, 2025, 25(8): 1254-1262.
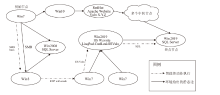
图1
攻击路径发现过程建模
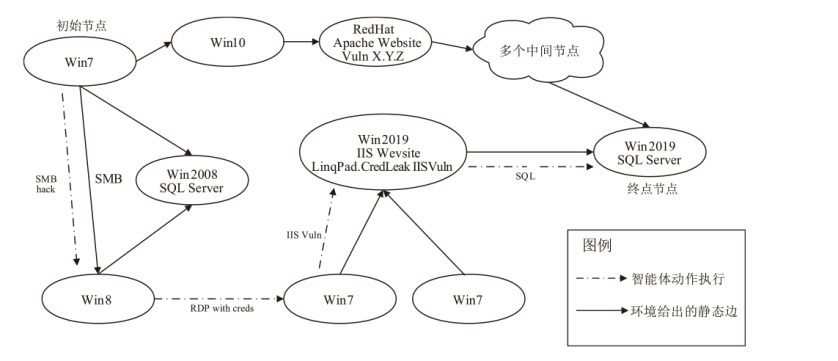
表1
环境建模方法
| 元素 | 表征对象 |
|---|---|
| 有向图 | 点表示网络节点,包含操作系统、开放端口、自定义漏洞、防火墙配置、奖励等信息;边表示其他节点的知识或节点间通信 |
| 环境 | 部分可观测、静态、离散的环境包含网络结构和智能体 |
| 动作空间 | 本地攻击、远程攻击、认证连接 |
| 观测空间 | 已发现节点、已获取节点、发现凭证、权限提升、可用攻击等 |
| 奖励 | 根据节点内在价值及动作代价定义 |
图2
智能体动作组成
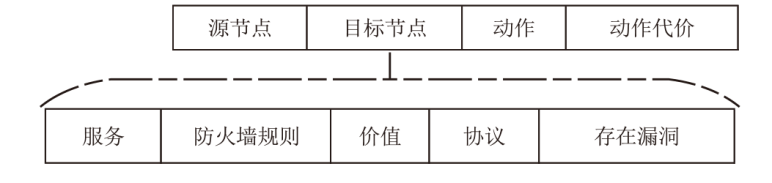
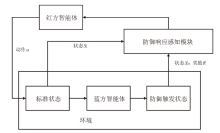
图3
AGF框架设计
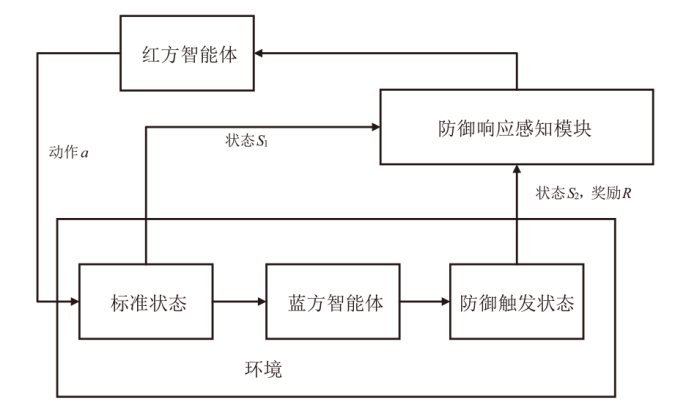
图4
典型业务网络建模
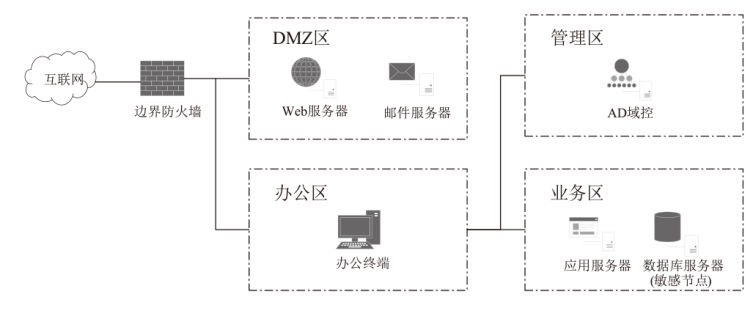
表2
节点配置信息
| 节点 | 编号 | 系统 | 核心服务(端口) |
|---|---|---|---|
| 边界防火墙 | (1, 1) | 专用防火墙OS | NAT/SSL VPN(443) |
| Web服务器 | (2, 1) | Linux | HTTP/HTTPS(80/443) |
| 邮件服务器 | (2, 2) | Exchange | SMTP/POP3/IMAP(25/110/143) |
| 办公终端 | (3,*) | Windows | AD认证(389/88) SMB (445) |
| 应用服务器 | (4, 1) | Linux | Tomcat(8080) RDP/SSH |
| 数据库服务器 | (4, 2) | Windows Server | 3306/1433 |
| AD 域控 | (5, 1) | Windows Server | LDAP/Kerberos(389/88) |
表3
漏洞及防火墙规则信息
| 节点 | 漏洞配置 | 防火墙规则 |
|---|---|---|
| (1, 1) | ACL错误配置 VPN漏洞 | 默认拒绝,仅允许业务端口 |
| (2, 1) | SQL注入 弱口令 | 入站:互联网→80/443 禁止:DMZ→内网 |
| (2, 2) | 邮件中继漏洞 弱加密 | 入站:互联网→25/110/143 禁止:主动连接内网 |
| (3,*) | 弱口令 未修复系统补丁 | 允许:业务区8080/445 禁止:3306/3389 |
| (4, 1) | Log4j漏洞 未限内部访问 | 允许:办公区→8080 禁止:DMZ区访问 |
| (4, 2) | 弱密码 未启用 SSL | 仅允许:应用服务器→3306 |
| (5, 1) | 黄金票据攻击 未启用LDAP签名 | 允许:全区域→389/88 禁止:主动连接 |
图5
训练阶段累积奖励变化情况
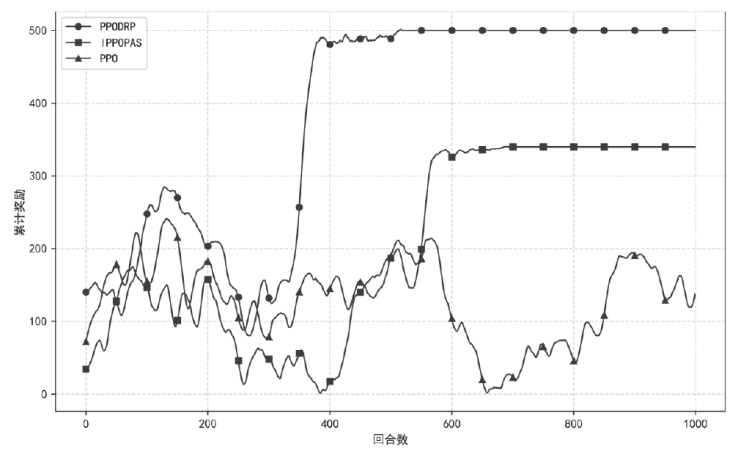
表4
红方智能体性能
| 方法 | 环境 | Reward_20 | Reward_30 | Reward_40 | Reward_50 | 最高回合奖励 |
|---|---|---|---|---|---|---|
| PPO | 测试 | 123.50 | 134.22 | 136.88 | 135.56 | 167 |
| PPODRP | 训练 | 218.43 | 213.75 | 213.38 | 214.36 | 276 |
| PPODRP | 测试 | 204.21 | 206.21 | 210.81 | 209.96 | 231 |
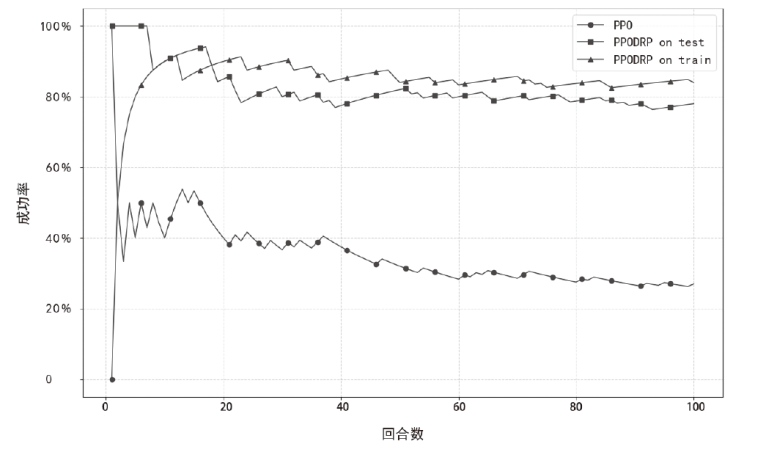
图6
路径发现成功率随评估回合数变化情况
| [1] | SUTTON R S, BARTO A G. Reinforcement Learning: An Introduction[J]. Robotica, 1999, 17(2): 229-235. |
| [2] | YU Kai, JIA Lei, CHEN Yuqiang, et al. Deep Learning: Yesterday, Today, and Tomorrow[J]. Journal of Computer Research and Development, 2013, 50(9): 1799-1804. |
| [3] | SILVER D, HUANG A, MADDISON C J, et al. Mastering the Game of Go with Deep Neural Networks and Tree Search[J]. Nature, 2016, 529(7587): 484-489. |
| [4] | ARKIN B, STENDER S, MCGRAW G. Software Penetration Testing[J]. IEEE Security & Privacy, 2005, 3(1): 84-87. |
| [5] | SINGH N, MEHERHOMJI V, CHANDAVARKAR B R. Automated Versus Manual Approach of Web Application Penetration Testing[C]// IEEE. 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT). New York: IEEE, 2020: 1-6. |
| [6] | STEFINKO Y, PISKOZUB A, BANAKH R. Manual and Automated Penetration Testing. Benefits and Drawbacks. Modern Tendency[C]// IEEE. 2016 13th International Conference on Modern Problems of Radio Engineering, Telecommunications and Computer Science (TCSET). New York: IEEE, 2016: 488-491. |
| [7] | ABU-DABASEH F, ALSHAMMARI E. Automated Penetration Testing: An Overview[EB/OL]. (2018-05-28)[2024-08-10]. https://doi.org/10.5121/CSIT.2018.80610. |
| [8] | MCKINNEL D R, DARGAHI T, DEHGHANTANHA A, et al. A Systematic Literature Review and Meta-Analysis on Artificial Intelligence in Penetration Testing and Vulnerability AssesSment[J]. Computers & Electrical Engineering, 2019, 75: 175-188. |
| [9] | POLATIDIS N, PAVLIDIS M, MOURATIDIS H. Cyber-Attack Path Discovery in a Dynamic Supply Chain Maritime Risk Management System[J]. Computer Standards & Interfaces, 2018, 56: 74-82. |
| [10] | HU Tairan, ZHOU Tianyang, ZANG Yichao, et al. APU-D* Lite: Attack Planning under Uncertainty Based on D* Lite[J]. CMC-Computers Materials & Continua, 2020, 65(2): 1795-1807. |
| [11] | SCHWARTZ J, KURNIAWATI H. Autonomous Penetration Testing Using Reinforcement Learning[EB/OL]. (2019-05-15)[2024-08-08]. https://doi.org/10.48550/arXiv.1905.05965. |
| [12] |
ZHOU Shicheng, LIU Jingju, ZHONG Xiaofeng, et al. Intelligent Penetration Testing Path Discovery Based on Deep Reinforcement Learning[J]. Computer Science, 2021, 48(7): 40-46.
doi: 10.11896/jsjkx.210400057 |
| [13] | NGUYEN H V, TEERAKANOK S, INOMATA A, et al. The Proposal of Double Agent Architecture Using Actor-Critic Algorithm for Penetration Testing[C]// INSTICC. 2021 7th International Conference on Information Systems Security and Privacy (ICISSP). Setubal: Science and Technology Publications, Lda,2021: 440-449. |
| [14] | ZENNARO F M, ERDODI L. Modelling Penetration Testing with Reinforcement Learning Using Capture-the-Flag Challenges: Trade-Offs between Model-Free Learning and a Priori Knowledge[J]. IET Information Security, 2023, 17(3): 441-457. |
| [15] | GAO Wenlong, ZHOU Tianyang, ZHAO Ziheng, et al. Network Attack Path Planning Method Based on Deep Reinforcement Learning[J]. Journal of Cyber Security, 2022, 7(5): 65-78. |
| 高文龙, 周天阳, 赵子恒, 等. 基于深度强化学习的网络攻击路径规划方法[J]. 信息安全学报, 2022, 7(5): 65-78. | |
| [16] | ZENG Qingwei, ZHANG Guomin, XING Changyou, et al. Intelligent Attack Path Discovery Based on Heuristic Reward Shaping Method[J]. Journal of Cyber Security, 2024, 9(3): 44-58. |
| 曾庆伟, 张国敏, 邢长友, 等. 基于启发式奖赏塑形方法的智能化攻击路径发现[J]. 信息安全学报, 2024, 9(3): 44-58. | |
| [17] | ZHANG Guomin, ZHANG Shaoyong, ZHANG Jinwei. Discovery and Optimization Method of Attack Paths Based on PPO Algorithm[J]. Netinfo Security, 2023, 23(9): 47-57. |
| 张国敏, 张少勇, 张津威. 基于PPO算法的攻击路径发现与寻优方法[J]. 信息网络安全, 2023, 23(9):47-57. | |
| [18] | WANG Yongjie. Research on the Development of Dynamic Defense Technology[J]. Secrecy Science and Technology, 2020 (6): 9-14. |
| 王永杰. 网络动态防御技术发展概况研究[J]. 保密科学技术, 2020 (6): 9-14. | |
| [19] | JAJODIA S, GHOSH A K, SWARUP V, et al. Moving Target Defense: Creating Asymmetric Uncertainty for Cyber Threats[M]. New York: Springer, 2011. |
| [20] | WU Jiangxing. Research on Cyber Mimic Defense[J]. Journal of Cyber Security, 2016, 1(4): 1-10. |
| 邬江兴. 网络空间拟态防御研究[J]. 信息安全学报, 2016, 1(4):1-10. | |
| [21] | TORQUATO M, MACIEL P, VIEIRA M. Security and Availability Modeling of VM Migration as Moving Target Defense[C]// IEEE. 2020 IEEE 25th Pacific Rim International Symposium on Dependable Computing (PRDC). New York: IEEE, 2020: 50-59. |
| [22] | WANG Jiang, ZHANG Zheng, MA Bolin, et al. Research on SSTI Attack Defense Technology Based on Instruction Set Randomization[C]// ACM. 2021 2nd International Conference on Artificial Intelligence and Information Systems. New York: ACM,2021: 1-5. |
| [23] | POSCHINGER R, RODDAY N, LABACA-CASTRO R, et al. Openmtd: A Framework for Efficient Network-Level MTD Evaluation[C]// ACM. Proceedings of the 7th ACM Workshop on Moving Target Defense. New York: ACM, 2020: 31-41. |
| [24] | HYDER M F, FAROOQ M U, AHMED U, et al. Towards Enhancing the Endpoint Security Using Moving Target Defense (Shuffle-Based Approach) in Software Defined Networking[J]. Engineering, Technology & Applied Science Research, 2021, 11(4): 7483-7488. |
| [25] | LIU Yaqun, ZHAO Jinlong, ZHANG Guomin, et al. Netobfu: A Lightweight and Efficient Network Topology Obfuscation Defense Scheme[EB/OL]. [2024-08-08]. https://doi.org/10.1016/j.cose.2021.102447. |
| [1] | 张国敏, 张少勇, 张津威. 基于PPO算法的攻击路径发现与寻优方法[J]. 信息网络安全, 2023, 23(9): 47-57. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||